
”flink 大数据 分布式 框架 文档“ 的搜索结果
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。这个学习文档通俗易懂flink知识点几乎全部覆盖,...
黑马程序员视频库播妞QQ号:3077485083传智播客旗下互联网资讯、学习资源免费分享平台随着信息时代的发展,大数据已经成为当今技术革新的一大发展趋势。在大数据时代,数据呈指数级增长,...
Flink 是一个以流为核心的高可用、高性能的分布式计算引擎。具备流批一体,高吞吐、低延迟,容错能力,大规模复杂计算等特点,在数据流上提供数据分发、通信等功能。

flink提交作业和执行任务,需要几个关键组件:客户端(client):代码由客户端获取并作转换,之后提交给 jobManagerJobManager:就是flink集群里的“管事人”,对作业进行中央调度管理;
大数据开源框架集锦.pdf
标签: 文档资料
14 数据可视化 Kibana ⽤于和 Elasticsearch ⼀起使⽤的开源的分析与可视化平台 15 数据挖掘 Mahout 基于hadoop的机器学习和数据挖掘的⼀个分布式框架 Spark MLlib Spark的机器学习库 MADlib 基于SQL的数据库内置的...


前言 Spark是一种大规模、快速计算...有关框架介绍和环境配置可以参考以下内容: 大数据处理框架Hadoop、Spark介绍 linux下Hadoop安装与环境配置 linux下Spark安装与环境配置 本文的参考配置为:Deepi...
Apache Flink 是一个流处理框架,用于实时数据处理和分析。它支持大规模数据流处理,具有高吞吐量和低延迟。Flink 的分布式部署和部署模式是其核心特性之一,使得 Flink 能够在大规模集群中有效地处理数据。 在本文...
主要基于对现阶段一些常用的大数据开源框架技术的整理,只是一些简单的介绍,并不是详细技术梳理。可能会有疏漏,发现再整理。参考得太多,就不一一列出来了。这只是作为一个梳理,对以后选型或者扩展的做个参考。
离线数据的分布式存储和计算基础框架 分布式存储HDFS 离线计算引擎MapReduce 资源调度Apache YARN 1.2 CDH 基于稳定版Hadoop及相关项目最成型的发行版本, 成为企业部署最广泛的大数据系统 可视化的UI界面中方便地...
bigdata
数据产品和数据密不可分作为数据产品经理理解数据从产生、存储到应用的整个流程,以及大数据建设需要采用的技术框架Hadoop是必备的知识清单,以此在搭建数据产品时能够从全局的视角理解从数据到产品化的价值。...
Apache Flink是一个顶级Apache项目,它允许统一分布式流和批处理。 Apache Flink的核心是流数据流引擎,该引擎为数据流上的分布式计算提供数据分发,通信和容错能力。 8月27日,湾区Apache Flink聚会活动由MapR...
内容来源:2018 年 5 月 5 日,小米HBase研发工程师吴国泉在“ACMUG &...阅读字数:2972 | 8分钟阅读获取嘉宾演讲视频及PPT:摘要大数据时代,各种分布式框架层出不穷,存储方面有: HDFS...
通过配置Flink作业和IntelliJ IDEA,并编写示例代码,我们可以方便地对分布式的Flink应用程序进行调试。...本文将介绍如何使用IntelliJ IDEA进行远程调试Flink大数据代码,并提供相应的源代码作为示例。
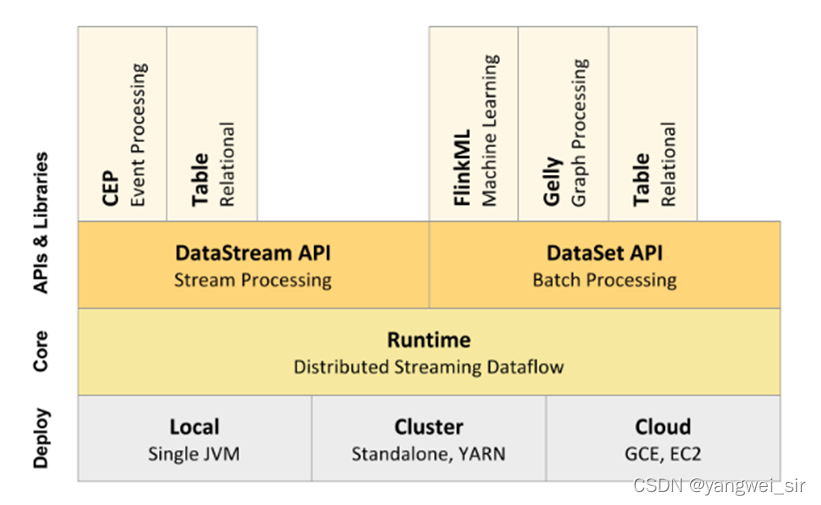
Apache Flink是一个面向数据流处理和批量数据处理的可分布式的开源计算框架,它基于同一个Flink流式执行模型(streaming execution model),能够支持流处理和批处理两种应用类型。由于流处理和批处理所提供的SLA...
Flink 是一个针对流数据和批数据分布式处理的引擎,在某些对实时性要求非常高的场景,基本上都是采用 Flink 来作为计算引擎,它不仅可以处理有界的批数据,还可以处理无界的流数据,在 Flink 的设计愿想...
任务和转换链 (tasks andtransformations chains) Job Managers, Task Managers, Clients 任务槽和资源(Task Slots and Resources) State Backends 保存点(savepoint) ...对于分布式执行,flink的转换...
支持多种数据源和数据目的地:Flink能够从多种数据源中读取数据,并将处理结果输出到多种数据目的地中,如Kafka、Hadoop、Cassandra、ElasticSearch等。这些优化手段可以提高Flink的性能和稳定性,保证Flink的高吞吐...
Spark or Flink ?:点击这里 Kafka 应用实践与生态集成:点击这里 Druid 深入分析Druid存储结构:点击这里 Kylin、Druid、ClickHouse核心技术对比:点击这里 ClickHouse ClickHouse的核心特性及架构:
大数据生态系统的主要开源技术和框架
大数据八股文(自用)
标签: 大数据
实现的逻辑是继承GenericUDF,重写evaluate方法,getdisplay方法。打包上传到hdfs路径上或者hive的lib目录 注册自定义的函数UDTF炸裂 一行多输出 TUDAF聚合多行输出一行Aggregate前台是和用户直接交互的界面和各种...
1. 前言 计算机的基本工作就是处理数据,包括磁盘文件中的数据,通过网络传输的数据流或数据包,数据库中的结构化数据等。随着互联网、物联网等技术得到越来越广泛的应用,数据规模不断增加,...而在分布式环境中...

Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。这个学习文档通俗易懂flink知识点几乎全部覆盖,...
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地